Задача этого курса – обучить вас разработке многопоточных приложений для Sun Solaris 10. Значительная часть полученных знаний может быть использована для разработки многопоточных приложений для других систем семейства Unix, поддерживающих POSIX threads API. Это такие системы, как Linux (начиная с версии 2.4),
Free BSD?, SCO Unixware, IBM AIX и др.
1. Что такое потоки
В Unix-системах для исполнения программ используются объекты, называемые процессами. Процессу выделяется собственное виртуальное адресное пространство и некоторые другие ресурсы. Для каждого процесса создается иллюзия последовательного исполнения. Программа исполняется в рамках процесса так же, как она исполнялась бы в однозадачной ОС.
Процесс взаимодействует с ядром ОС при помощи так называемых системных вызовов. При исполнении системного вызова, процесс исполняет специальную команду (у современных версий x86 эта команда называется SYSCALL, у SPARC – TA 0x8 для 32-битных программ, TA 0x40 для 64-битных программ), которая переключает адресное пространство и передает управление ядру. Процессы в традиционных Unix-системах могут взаимодействовать друг с другом только при помощи системных вызовов – чтения и записи в трубы и разделяемые файлы, а в более современных системах – при помощи System V IPC.
Таким образом, процессы в Unix надежно изолированы друг от друга. Нарушения целостности данных одного процесса (например, в результате переполнения буфера или ошибок при работе с указателями) приводят к аварийному завершению этого процесса, но не затрагивают, во всяком случае, непосредственно, другие процессы. Даже удаленное исполнение кода в рамках одного из процессов приводит только к тому, что злоумышленник, написавший этот код, получает лишь те привилегии, которые имел этот процесс.
Однако ряд задач – примеры которых мы рассмотрим далее в этом разделе – требует реализации в виде нескольких параллельно (или, на однопроцессорной машине, квазипараллельно) исполняющихся процессов. Традиционные Unix-системы предполагали решать такие задачи при помощи нескольких взаимодействующих процессов. Среди системных вызовов, поддерживаемых всеми современными Unix-системами можно выделить несколько групп, специально предназначенных для такого взаимодействия – это вызовы для работы с трубами (pipe), сетевые средства (которые можно применять и для взаимодействия между процессами на одной машине) и System V IPC. К сожалению, далеко не для всех задач эти средства оптимальны, а для некоторых и вовсе неадекватны.
Кроме того, нередко возникала потребность в переносе приложений, разработанных для ОС, допускавших несколько нитей исполнения в пределах одной задачи или процесса, под Unix.
Поэтому в современных Unix-системах было введено понятие нитей (thread), которые соответствуют единицам планирования в рамках одного процесса. Нити разделяют общее адресное пространство, но планируются независимо. Иллюзия последовательного исполнения создается для нити, а не для процесса в целом.
1. Зачем нужны многопоточные программы
- Улучшение времени реакции интерактивных программ. Примеры: фоновое скачивание страницы в браузере, фоновая проверка орфографии, фоновое переразбиение текста на страницы в WYSIWYG текстовых процессорах.
- Улучшение времени реакции серверных приложений. Возможность обрабатывать несколько запросов одновременно.
- Использование дополнительных ресурсов на многопроцессорных и гипертрединговых компьютерах.
- Задачи реального времени
1.1 Улучшение времени реакции серверных приложений
Главные характеристики большинства серверов приложений – это среднее время исполнения запроса и количество запросов, обрабатываемых в единицу времени. Это две разные характеристики.
Среднее время исполнения запроса – это основная характеристика производительности сервера с точки зрения отдельного пользователя. Увеличение этого времени ведет к снижению производительности пользователя, ему приходится тратить больше времени на исполнение тех же самых задач. Кроме того, слишком большое время реакции системы попросту раздражает пользователей.
Количество запросов, обрабатываемых в единицу времени – это основная характеристика производительности сервера с точки зрения владельца этого сервера. Если мы найдем способ увеличить это количество, не ухудшив или незначительно ухудшив показатели исполнения отдельных запросов, мы сможем подключить к серверу больше пользователей. Таким образом, владелец сервера может сэкономить на приобретении оборудования.
Рассмотрим процесс исполнения одиночного запроса типичным серверным приложением (см. рис. 1). Он состоит из пяти этапов: приема запроса (выполняется сетевым интерфейсом), анализа запроса (выполняется центральным процессором), считывания данных с диска (выполняется дисковым контроллером), создания ответа (выполняется центральным процессором) и передачи ответа. Разумеется, времена исполнения этих этапов могут различаться в зависимости от типа сервиса, предоставляемого сервером, и от самих запросов. Для сервера http, раздающего статические HTML страницы, время анализа запроса и форматирования ответа будет очень малым по сравнению с временами чтения с диска и передачи данных по сети. Напротив, у сервера приложений основная нагрузка ляжет на центральный процессор. Серверу баз данных может потребоваться несколько обращений к диску для того, чтобы найти все относящиеся к запросу данные, и т.д.. Тем не менее, давайте рассмотрим условный сервер, обрабатывающий однотипные запросы, у которых структура обработки запроса именно такова, как на рис. 1, а времена исполнения всех этапов одинаковы (последнее требование нужно лишь для того, чтобы мне было проще рисовать картинку).
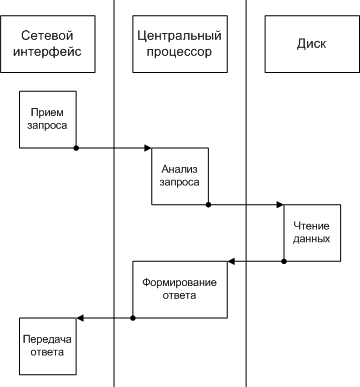
Рис. 1 Исполнение одиночного запроса серверным приложением.
Рассмотрим теперь исполнение потока запросов. Однопоточный сервер должен был бы исполнять запросы строго последовательно, поэтому максимальное количество запросов, исполняемых в секунду, было бы равно 1/t, где t – время исполнения одиночного запроса. При этом среднее время исполнения запроса не будет равно t, а будет расти в зависимости от вероятности перекрытия запросов во времени. Теоретико-вероятностные расчеты и практика показывают, что когда поток запросов приближается к 1/t в секунду, эта вероятность становится весьма значительной, так что время исполнения одиночного запроса может увеличиться во много раз.
Однако к многопоточному серверу эти расчеты неприменимы. Рассмотрим, как многопоточный сервер мог бы обрабатывать поток запросов (см. рис. 2).
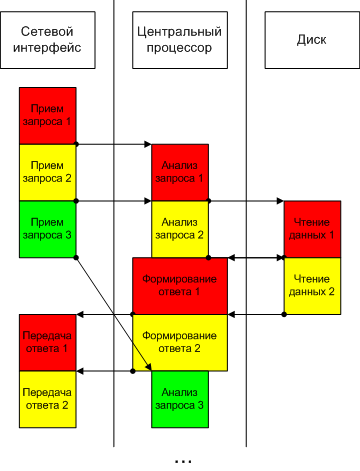
Рис. 2 Исполнение потока запросов многопоточным сервером.
Видно, что сервер совмещает этапы исполнения перекрывающихся во времени запросов. Если относительные времена исполнения этапов запросов таковы, как на рис. 1 и 2, избежать взаимодействия запросов не удается, так что среднее время исполнения запроса может вырасти по сравнению с t. Но количество запросов, исполняемых в секунду, оказывается значительно больше, чем 1/t.
Более того, видно, что мы могли бы повысить производительность системы, установив второй процессор и второй сетевой интерфейс.
Однако переделка однопоточного серверного приложения в многопоточное требует специальной поддержки со стороны операционной системы и значительной переработки кода приложения. Все современные ОС общего назначения – Sun Solaris, другие системы семейства Unix, IBM zOS,
Win 32? и
Win 64? – обеспечивают соответствующую поддерку, но далеко не все разработчики приложений умеют этой поддержкой пользоваться.
2. Архитектуры многопоточных приложений
- Многопроцессные приложения с автономными процессами
- Многопроцессные приложения, взаимодействующие через трубы, сокеты и очереди System V IPC
- Многопроцессные приложения, взаимодействующие через разделяемую память
- Собственно многопоточные приложения
- Событийно-ориентированные приложения
- Гибридные архитектуры
2.1 Многопроцессные приложения с автономными процессами
Это самый простой тип многопроцессных приложений. Для каждой пользовательской сессии или даже для каждого запроса создается свой процесс. Он обрабатывает запрос или несколько запросов и завершается.
Преимущества:
- Простота разработки. Фактически, мы запускаем много копий однопоточного сервера и они работают независимо друг от друга. Можно не использовать никаких специфически многопоточных API и средств межпроцессного взаимодействия.
- Высокая надежность. Аварийное завершение любого из серверных процессов никак не затрагивает остальные серверные процессы.
- Хорошая переносимость. Приложение будет работать на любой многозадачной ОС
- Высокая безопасность. Разные процессы приложения могут запускаться от имени разных пользователей. Таким образом можно реализовать принцип минимальных привилегий, когда каждый из процессов имеет лишь те права, которые необходимы ему для работы. Даже если в каком-то из процессов будет обнаружена ошибка, допускающая удаленное исполнение кода, взломщик сможет получить лишь уровень доступа, с которым исполнялся этот процесс.
Недостатки:
- Далеко не все сервисы можно предоставлять таким образом. Например, эта архитектура годится для раздачи статических HTML-страниц, но совсем непригодна для сервера баз данных и многих серверов приложений.
- Создание и уничтожение процессов – дорогая операция, поэтому для многих задач такая архитектура неоптимальна.
Примеры: apache 1.x (сервер HTTP)
2.2 Многопроцессные приложения, взаимодействующие через сокеты, трубы и очереди сообщений System V IPC
Перечисленные средства IPC (Interprocess communication) относятся к так называемым средстам гармонического межпроцессного взаимодействия. Они позволяют организовать взаимодействие процессов и потоков без использования разделяемой памяти. Как мы увидим дальше, это дает значительные преимущества.
Преимущества:
- Относительная простота разработки. Теоретики программирования очень любят эту архитектуру, потому что она позволяет избежать специфических ошибок программирования (так называемых ошибок соревнования), характерных для многопоточных программ, которые очень сложно обнаруживать при тестировании. Большая часть нашего курса посвящена тому, как избежать ошибок соревнования при разработке многопоточных программ.
- Высокая надежность. Аварийное завершение одного из серверных процессов приводит к закрытию трубы или сокета, а в случае очередей сообщений – к тому, что сообщения перестают поступать в очередь или извлекаться из нее. Остальные процессы приложения легко могут обнаружить эту ошибку и восстановиться после нее, возможно (но не обязательно) просто перезапустив отказавший процесс.
- Многие такие приложения (особенно основанные на использовании сокетов) легко переделываются для исполнения в распределенной среде, когда разные компоненты приложения исполняются на разных машинах.
- Хорошая переносимость. Приложение будет работать на большинстве многозадачных ОС, в том числе на старых Unix-системах.
- Высокая безопасность. Разные процессы приложения могут запускаться от имени разных пользователей. Таким образом можно реализовать принцип минимальных привилегий, когда каждый из процессов имеет лишь те права, которые необходимы ему для работы.
Даже если в каком-то из процессов будет обнаружена ошибка, допускающая удаленное исполнение кода, взломщик сможет получить лишь уровень доступа, с которым исполнялся этот процесс.
Недостатки:
- Не для всех типов сервисов такую архитектуру легко разработать и реализовать.
- Все перечисленные типы средств IPC предполагают последовательную передачу данных. Если необходим произвольный доступ к разделяемым данным, такая архитектура неудобна.
- Передача данных через трубу, сокет и очередь сообщений требует исполнения системных вызовов и двойного копирования данных – сначала из адресного пространства исходного процесса в адресное пространство ядра, затем из адресного пространства ядра в память целевого процесса. Это дорогие операции. При передаче больших объемов данных это может превратиться в серьезную проблему.
- В большинстве систем действуют ограничения на общее количество труб, сокетов и средств IPC. Так, в Solaris по умолчанию допускается не более 1024 открытых труб, сокетов и файлов на процесс (это обусловлено ограничениями системного вызова select). Архитектурное ограничение Solaris – 65536 труб, сокетов и файлов на процесс. Ограничение на общее количество сокетов TCP/IP – не более 65536 на сетевой интерфейс (обусловлено форматом заголовков TCP). Очереди сообщений System V IPC размещаются в адресном пространстве ядра, поэтому действуют жесткие ограничения на количество очередей в системе и на объем и количество одновременно находящихся в очередях сообщений.
- Создание и уничтожение процесса, а также переключение между процессами – дорогие операции. Не во всех случаях такая архитектура оптимальна.
2.3 Многопроцессные приложения, взаимодействующие через разделяемую память
В качестве разделяемой памяти может использоваться разделяемая память System V IPC и отображение файлов на память. Для синхронизации доступа можно использовать семафоры System V IPC, мутексы и семафоры POSIX, при отображении файлов на память – захват участков файла.
Преимущества:
- Эффективный произвольный доступ к разделяемым данным. Такая архитектура пригодна для реализации серверов баз данных.
- Высокая переносимость. Может быть перенесено на любую операционную систему, поддерживающую или эмулирующую System V IPC.
- Относительно высокая безопасность. Разные процессы приложения могут запускаться от имени разных пользователей. Таким образом можно реализовать принцип минимальных привилегий, когда каждый из процессов имеет лишь те права, которые необходимы ему для работы. Однако разделение уровней доступа не такое жесткое, как в ранее рассмотренных архитектурах.
Недостатки:
- Относительная сложность разработки. Ошибки при синхронизации доступа – так называемые ошибки соревнования – очень сложно обнаруживать при тестировании. Это может привести к повышению общей стоимости разработки в 3–5 раз по сравнению с однопоточными или более простыми многозадачными архитектурами.
- Низкая надежность. Аварийное завершение любого из процессов приложения может оставить (и часто оставляет) разделяемую память в несогласованном состояниии. Это часто приводит к аварийному завершению остальных задач приложения. Некоторые приложения, например Lotus Domino, специально убивают все серверные процессы при аварийном завершении любого из них.
- Создание и уничтожение процесса и переключение между ними – дорогие операции. Поэтому данная архитектура оптимальна не для всех приложений.
- При определенных обстоятельствах, использование разделяемой памяти может приводить к эскалации привилегий. Если в одном из процессов будет найдена ошибка, приводящая к удаленному исполнению кода, с высокой вероятностью взломщик сможет ее использовать для удаленного исполнения кода в других процессах приложения. То есть, в худшем случае, взломщик может получить уровень доступа, соответствующий наивысшему из уровней доступа процессов приложения.
Фактически, данная архитектура сочетает недостатки многопроцессных и собственно многопоточных приложений. Тем не менее, ряд популярных приложений, разработанных в 80е и начале начале 90х, до того, как в Unix были стандартизованы многопоточные API, используют эту архитектуру. Это многие серверы баз данных, как коммерческие (Oracle, DB2, Lotus Domino), так и свободно распространяемые, современные версии Sendmail и некоторые другие почтовые серверы.
2.4 Собственно многопоточные приложения
Потоки – э