Relational Database Replication
Описание проекта
Для хранения данных приложений в большинстве случаев используются реляционные системы управления базами данных. С их помощью легко составлять различные отчеты, в том числе достаточно сложные (OLAP, data mining) и решать прочие прикладные задачи. Проблемы возникают при работе с распределенными данными, когда объединенным в сеть узлам с обособленными хранилищами необходимо синхронизировать содержимое своих БД. С точки зрения каждого узла такой сети, его хранилище является локальной репликой, хранилища же других узлов – удаленными репликами. Реплицируя лишь строки таблиц, невозможно обеспечить целостность отношений между таблицами. Существует ряд решений для репликации реляционных СУБД, но большинство из них специфичны для конкретной СУБД и несовместимы между собой. В общем случае возможно несколько способов синхронизации данных: при обращении к СУБД на запись соответствующая транзакция проводится на всех синхронизируемых узлах одновременно; создается дамп всей БД одного узла и имортируется в БД другого; используются специфичные для конкретной СУБД средства. Большинство из этих решений неприменимы в сети с низкой отказоустойчивостью и низкой скоростью передачи данных, в особенности первый способ, где отключение узла от сети приводит к необходимости использования других средств для синхронизации с другими узлами кластера. Передача дампа БД по сети с пропускной способностью в несколько десятков КБ/сек может занять очень длительное время, за которое данные на узлах изменятся так, что необходимо будет повторить процесс заново. Таким образом, механизм репликации для таких сетей должен обладать рядом свойств:
- поддерживать продолжение репликации после обрыва связи
- передавать минимальное количество информации, в идеале — только данные об изменениях
- быть универсальным как с точки зрения работы с различными СУБД, так и с точки зрения реализации на различных языках программирования.
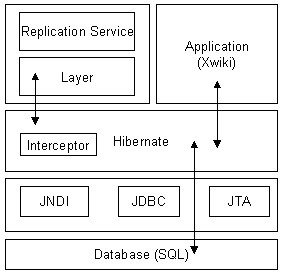
Проект «Relational database replication» (RDBR) был создан как раз для того, чтобы разработать и реализовать механизм offline-репликации для реляционных СУБД. Ключевым моментом является то, что RBDR предусматривает наличие дополнительного слоя в структуре данных. Большинство современных приложений для работы с реляционными хранилищами используют механизм объектно-реляционного отображения, когда объекты бизнес-логики транслируются в строки таблиц БД. При этом нередко целостность данных сводится к поддержанию целостности состояния отдельных объектов (многие реальные приложения осуществляют транзакции над группами объектов одновременно, но часто это делается скорее для повышения производительности, чем для обеспечения целостности). В этих условиях, для обеспечения целостности данных может оказаться достаточно осуществлять репликацию на уровне объектов. Именно эта идея используется в RDBR. Принцип его работы выглядит примерно так: для каждого объекта на все время его жизни создается служебная информация, которая включает в себя уникальный в рамках всей сети идентификатор этого объекта, время сохранения его в локальной реплике и время фактической модификации его атрибутов. Как показывает опыт Lotus Notes/Domino, этого вполне достаточно для организации репликации методом «распространения слухов». Каждый узел по запросу составляет специальный документ, содержащий описанную выше метаинформацию об измененных с даты последней удачной репликации объектов, затем узлы обмениваются этой информацией, разрешаются возможные конфликты несогласованных модификаций в обеих репликах, накладываются различные фильтры, а затем по полученной информации составляются списки объектов для отправки. Таким образом, можно выделить основные составляющие такого механизма, это: как можно более стандартизированный формат записи метаинформации и самих объектов, клиент-серверная часть, реализующая непосредственно обмен данными, средства объектно-реляционного отображения. В качестве последнего было решено использовать популярную библиотеку Hibernate, имеющую реализацию на языках Java и C#. В качестве стандартизированного формата представления данных используется XML (для обмена метаинформацией используется протокол RSS). Клиент-серверную часть решено было реализовать в виде web-приложения на языке Java для сервера Apache Tomcat. В качестве тестового приложения используется система управления контентом Xwiki, также представляющая собой web-приложение Tomcat. Для сбора метаинформации используется предложенный разработчиками Hibernate интерфейс Interceptor, методы которого вызываются при обращениях в СУБД. Таким образом, модификация Hibernate должна быть прозрачной для бизнес-приложения, что позволит внедрить RDBR в уже существующие системы. Теперь несколько слов о структуре самого проекта, схематично изображенного на следующем рисунке:

Отсюда видно, что приложение никак не связано с системой репликации. А система репликации связана с СУБД посредством библиотеки Layer, что позволяет заменить лишь её при использовании другой библиотеки ORM, нежели Hibernate. Replication Service представляет собой сервер репликатора (набор Java-сервлетов, обрабатывающих HTTP-запросы) и сервис, исполняющий активную роль (клиент, который инициирует соединение с сервером на другом узле).
Возвращаясь к описанным выше требованиям к механизму offline-репликации, следует отметить, что RBDR удовлетворяет всем трем пунктам. После обрыва репликации (например, повреждение сетевого кабеля) она будет продолжена во время следующего сеанса. Это обеспечено за счет того, что под транзакцией в данном случае понимается передача каждого отдельного объекта. Передаваемые данные содержат в себе информацию только о тех изменениях, которые произошли после последнего удачного сеанса репликации, что резко снижает количество передаваемых данных. Использование XML для представления метаинформации и состояния объектов, а также разделение на Replication Service и Layer позволяет использовать не только технологии Java, но и любые другие, поддерживающие ORM, а выделение серверной компоненты предоставляет возможность написания отдельных приложений-клиентов, реализованных любым возможным способом.
Однако, эти отличительные черты RDBR накладывают ряд ограничений и требований к бизнес-приложению как в отношении модели БД, так и в отношении обработки исключительных случаев, когда приложению будет доступно частично отреплицированное множество объектов. К тому же, должен существовать алгоритм составления уникальных идентификаторов объекта. Также должен существовать метод разрешения конфликтов несогласованной модификации. На текущий момент составляются требования к организации БД и производятся соответствующие исправления в выбранном для тестирования приложении — Xwiki.
В данном решении узлы репликационной сети обмениваются информацией в режиме «один к одному», еще не поддерживается частичная репликация. Следующий прототип будет обеспечивать одновременную репликацию с несколькими узлами, полную автоматизацию управления репликацией, представленную выделенным узлом-менеджером и соответствующим протоколом обмена данными между менеджером и остальными узлами. Возможным будет как ручное редактирование топологии репликационной сети, так и автоматическое, основанное на статистике частоты изменений на узле, скорости обмена данными с узлом и средней нагрузки. В дальнейшем планируется реализация частичной репликации.
 rdbr_struct.png
rdbr_struct.png